42tokyo Advent Calendar 2022 の5日目を担当する、42tokyo在校生のJUNです。
42Tokyo の課題の1つである webserv
課題概要
課題の概要を箇条書きで書くと、以下のようになります。
C++ 98 でイベント駆動、非同期IOを使ってHTTPサーバーを書く。
ただし、Nginxのように1つのMasterプロセスと複数のWorkerプロセスで稼働するマルチプロセスの構成ではなく、Workerプロセスが1つだけあるシングルプロセスシングルスレッドの構成。
OSのソケットインターフェースを用いてクライアントと通信する。
Nginxのようにノンブロッキング I/OとI/O多重化を用いてリクエス トを処理する。Apache のようにリクエス トごとにForkしない。
CGI に対応させる。
1チーム2~3人のチーム課題。
提出したコード
github.com
42Tokyoでは課題を学生同士でレビューし、レビュワーがレビューイーの提出したコードを確認することで課題が合格基準に満たしているかを確認します。そのための資料を review.md として用意しました。基本的な動作確認や、何ができるかなどはこのファイルを見ればわかるようになっています。
プログラム全体の流れ
プログラム全体の流れとしては
Configをパースして、それをもとにServerインスタンス を作成
イベントループを開始する。以下のイベントループを繰り返す。
タイムアウト したソケットが無いか確認するepoll_wait でイベントが発生したfdが出現するまで待つ
イベントが発生したfdがあればそれに紐付けられたハンドラー(関数ポインタ)が呼ばれる。
イベントが接続待ちソケット(参考: listen )から発生した場合は新規クライアントの接続要求なのでそれを処理する
イベントが接続済みソケットから発生した場合は以下の2つのパターンがある
Readイベントが発生したときには、HTTPのパースを行い、メソッドやリクエス ト先のパスなどに応じて処理を行い、レスポンスを生成する。
Writeイベント(writableと言った方がわかりやすいかも?)が発生したときには、生成しておいたレスポンスデータをソケットに書き込むことでクライアントにデータを送信する。
UNIX ドメイン ソケット(親プロセスとCGI プロセスの通信用)から発生した場合は以下の2パターン
Writeイベントが発生したときには、UNIX ドメイン ソケットにデータを書き込み、CGI プロセスへデータを渡す。
Readイベントが発生したときには、UNIX ドメイン ソケットからデータを読み込み、CGI プロセスが出力したデータを受け取る。
イベントループの最初に戻る
といったような内容になっています。見て分かる通り、基本的にはイベントループ内の処理がコードの大部分を占めます。
用語説明
この課題に取り組む上で重要な単語をいくつかご紹介。
イベント駆動型プログラム
まずイベント駆動型プログラムについて説明する前に、より馴染みのあるフロー駆動型プログラムについて説明する。
フロー駆動型プログラムとは、上から下に順次実行され、条件分岐や繰り返し処理があるとそれに従う。プログラムは流れ(Flow)を記述することになるのでフロー駆動型プログラムと呼ばれる。
それに対し、イベント駆動型プログラムは、様々なイベントに対応する処理を定義し、イベントの発生に応じてプログラムの流れは変化するようなプログラムのことを指す。このようなプログラムの場合、必要なことは「イベントの監視」と「イベントに対応する処理の定義」である。
イベントには様々なものがあるが、イメージしやすいものだと以下のようなものがある。
GUI アプリケーショにおけるユーザーの操作。マウスクリック、キー入力など。ネットワークからのデータ受信。
シグナルの受信。
ノンブロッキング I/Oとは、I/O処理を行おうとした際にOS側がまだI/Oを行う準備が出来ていない場合に、I/Oが処理が完了するまで待つのではなく、即座にI/Oシステムコール が返るようなものである。
UNIX 系の場合、fcntl を使い、fcntl(fd, F_SETFL, O_NONBLOCK) とすることで対象fdをノンブロッキング I/Oとして扱える。
例えば、以下のように標準入力をノンブロッキング I/Oにしてみるとわかりやすい。
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#include <sys/errno.h>
#define BUF_SIZE 100
int main (int argc, char ** argv){
char buf[BUF_SIZE];
int rd;
#ifdef NONBLOCK
fcntl (STDIN_FILENO, F_SETFL, O_NONBLOCK);
#endif
while ((rd = read (STDIN_FILENO, buf, BUF_SIZE - 1 )) < 0 ) {
printf ("ノンブロッキングI/Oで返された。rd: %d , errno: %d , %s\n " , rd, errno , strerror (errno ));
sleep (1 );
}
buf[rd] = '\0' ;
printf ("入力された。rd: %d , %s\n " , rd, buf);
return 0 ;
}
ブロッキング I/O(fcntl(STDIN_FILENO, F_SETFL, O_NONBLOCK);しない)で実行すると以下のように、read()システムコール でデータが読み取れるまで(ユーザーが入力するまで)read()からは返らない。
$ gcc io_test.c && ./a.out < /dev/tty
hoge
入力された。rd: 5, hoge
これに対し、ノンブロッキング I/O(fcntl(STDIN_FILENO, F_SETFL, O_NONBLOCK);する)で実行すると、read() システムコール でデータが読み込めない(ユーザーがまだ入力してない)場合にもread()から返り、返り値は-1で、errnoは35(EAGAIN)となった。
$ gcc -DNONBLOCK io_test.c && ./a.out < /dev/tty
ノンブロッキングI/Oで返された。rd: -1, errno: 35, Resource temporarily unavailable
ノンブロッキングI/Oで返された。rd: -1, errno: 35, Resource temporarily unavailable
ノンブロッキングI/Oで返された。rd: -1, errno: 35, Resource temporarily unavailable
hoge
入力された。rd: 5, hoge
このように、ノンブロッキング I/Oをfdにセットすると、I/Oシステムコール を呼び出した際に対象fdがまだ対応できる状態ではない(読み込めない or 書き込めない)場合に、そのI/O処理が完了するまで待つ(ブロッキング )のではなく、即座に返す(ノンブロッキング )。
I/O多重化
I/Oの多重化とは、複数のI/Oデバイス (fd)を同時に扱う方法であり、UNIX においては select, poll, epoll(Linux 限定), kqueue(FreeBSD 系) などのシステムコール を用いて実現されるものである。また、今回のイベントループにおけるイベント監視もこれを用いて実現する。
これらのシステムコール の使い方としては、まず初めに監視したいfdを登録し、次にイベントが発生したかどうか取得するシステムコール を呼び出して、I/O可能になったfdを取り出す。その後そのfdに対してどのようなイベントが可能になったかを取得し、それに応じた処理をする。
今回の課題では、I/O多重化を行い以下のfdを監視した
また、I/O多重化を行うシステムコール と非同期I/Oを組み合わせることで、非常に効率的に多くのfdを同時に扱うことができる。
注意として、ここでfdを同時に扱う と言っているのは、同時に入出力ができるという意味ではなく、1つのプロセスで多くのfdの状態を同時に監視できるということである。
epoll の場合だと、以下のようなシステムコール がある。
epoll_create: Epollインスタンス の初期化epoll_ctl: Epollに対して監視するfdを追加したり削除したり。epoll_wait: 監視しているfdの中でI/Oイベントが発生したものを取得。
linuxjm.osdn.jp
ちなみに、ここで紹介した select, poll, epoll, kqueue だが、I/Oイベントの取得の計算量に違いがあり、n を監視対象のfdの数とすると、select と poll が O(n) で、epoll と kequeue が O(1) である。
自分のチームは今回動作環境をLinux に限定し、使うAPI はepollにした。
ソケット
ソケットとは、ネットワーク通信やプロセス間通信のAPI である。これによりプログラマー は簡単にTCP やUDP を用いたネットワーク通信、UnixDomainSocketを使ったプロセス間通信が可能になる。
en.wikipedia.org
Config
ここから実装した内容とかそのTipsとかに付いて書いていく。
Configに関してはNginxのものを参考に仕様を定め、BNF を書き、それに基づきシンプルな再帰 下降構文解析 法でパースした。
github.com
イベントループ
イベントループは今回の課題の肝となる部分
Epollの抽象化
epoll に関しては Android のソースコード を参考に、Epollクラスを作成した。このクラスはただ単に epoll のシステムコール をクラスのメソッドにするのではなく、イベントも独自に再定義し、epoll のイベントから独自に定義したイベントに変換できるようにした。これによって、タイムアウト などの独自で定義したイベントを扱えるようになった。
github.com
初期化
Configでの情報をもとに必要なTCP 接続待ちソケットを作成する。
例えば以下のようなConfigが渡された場合
server {
listen 127.0.0.1:80;
location / {
// 省略
}
}
server {
listen 127.0.0.1:80;
server_name webserv.com;
location / {
// 省略
}
}
server {
listen 127.0.0.2:80;
location / {
// 省略
}
}
server {
listen 8080;
location / {
// 省略
}
}
以下の接続待ちTCP ソケットを作成し、イベントループ開始前に Epoll に登録する。
listen 127.0.0.1:80 が2つあるが、これはHTTPのHostヘッダーをもとに振り分けを行い、1つの接続先であたかも2つのサーバーが動いているかのように動作する機能である。
nginx.org
イベントループのコード
上記のEpollクラスによる抽象化が功を奏し、イベントループは以下のようにシンプルなものになった。
int StartEventLoop (Epoll &epoll) {
while (1 ) {
std ::vector <FdEventEvent> timeouts = epoll.RetrieveTimeouts ();
for (std ::vector <FdEventEvent>::const_iterator it = timeouts.begin ();
it != timeouts.end (); ++it) {
FdEvent *fde = it->fde;
unsigned int events = it->events;
InvokeFdEvent (fde, events, &epoll);
}
Result<std ::vector <FdEventEvent> > result = epoll.WaitEvents (100 );
if (result.IsErr ()) {
utils::ErrExit ("WaitEvents" );
}
std ::vector <FdEventEvent> fdees = result.Ok ();
for (std ::vector <FdEventEvent>::const_iterator it = fdees.begin ();
it != fdees.end (); ++it) {
FdEvent *fde = it->fde;
unsigned int events = it->events;
InvokeFdEvent (fde, events, &epoll);
}
}
}
また、InvokeFdEvent() では事前にepollにfdを登録する際に設定したハンドラー(関数ポインタ)を呼び出すような仕組みになっており、以下のような共通のインターフェースを持つようにした。
void HandleHogeEvent (FdEvent *fde, unsigned int events, void *data, Epoll *epoll)
ここでの各種引数は以下のようになっている。
fde: 監視対象のfdの情報。タイムアウト の秒数やどのイベントを監視するかを保持している。
events: epoll_wait で取得したイベントを独自のイベントに変換したもの。
data: 渡したいデータ。クラスインスタンス のポインタであることが多い。 reinterpret_cast<ConnSocket *>(data); こんな感じでキャストして使っている。
epoll: epollインスタンス のポインタ。
基本的にこれらの引数があれば今回の課題の範囲内ではすべての処理が行えました。
今回は以下のようなイベントハンドラ ー関数を定義しました。
HandleListenSocketEvent: 接続待ちソケットに対するイベントハンドラ ー
Readイベントが発生した場合は、accept() して接続済みソケットインスタンス を作成し、Epollの監視対象に加える。
HandleConnSocketEvent: 接続済みソケットに対するイベントハンドラ ー
Readイベントが発生した場合は、クライアントからのデータを読み取り、HTTPリクエス トとしてパースする。
Writeイベントが発生した場合は、返すべきレスポンスがあればソケットに書き込み、クライアントに送信する。
HandleCgiEvent: CGI プロセスとの通信用のUnixDomainSocketに対するイベントハンドラ ー
Writeイベントが発生した場合は、CGI リクエス トとして送信するべきBodyがあればソケットに書き込み、CGI プロセスが標準入力として受け取れるようにする。
Readイベントが発生した場合は、CGI レスポンスがある場合はそれを読み取り、CGI レスポンスの種類を解析する。(CGI レスポンスの種類については後述)
HTTPリクエス トのパース
HTTPリクエス トのパースに関してはチームメンバーの人がやってくれたので自分は特に詳しくは知らないですが、基本的には RFC 9112 — HTTP/1.1 に従う形で実装したはず。偉大。
静的ファイルに対するリクエス ト
HTTPリクエス トを解析した結果、リクエス トが先がCGI ではなく、尚且つディレクト リでも無い場合には標準ファイルへのリクエス トと判断する。
ちなみにディレクト リへのGETリクエス トはautoindexの画面を動的に生成し、返す。(あのファイル一覧が載ってるページね)
ファイルへのリクエス トがGETメソッドだった場合は普通にHTTPレスポンスを生成し、クライアントへ返す。
ファイルへのリクエス トがPOSTもしくはDELETEの場合でかつ、リクエス ト先がアップロード可能なディレクト リの場合にはファイル作成や削除を行う。この課題要件は正直あまり好きではないのだが、共有ファイルサーバーと考えれば受け入れられるかも...?
リクエス ト先がCGI のディレクト リ(Configで特定のディレクト リに対する操作はCGI として扱う設定を規定している)だった場合、CGI の処理を開始する。
CGI の実装は基本的に RFC3875 - The Common Gateway Interface (CGI) Version 1.1 日本語訳 をベースに実装した。
CGI リクエス トが来たら、CGI として実行するプログラムを特定し、CGI プログラムが存在した場合に実行する。実行時にはCGI プロセスとの通信用のUnixDomainSocketを準備し、RFC にて定められている環境変数 をセットしてから fork() & execve() する。
ちなみにCGI に関するConfigは以下のようにConfigファイルに書いてある。
server {
listen 127.0.0.1:80;
server_name webserv.com;
location / {
allow_method GET;
root /var/webserv/server2/;
index index.html;
}
location /cgi-bin {
is_cgi on;
cgi_executor python3;
allow_method GET POST DELETE;
root /var/webserv/server2/cgi-bin;
index index.cgi;
}
location_back .py {
is_cgi on;
cgi_executor python3;
allow_method GET POST DELETE;
root /var/webserv/server2/cgi-py/;
}
location /cgi-bash {
is_cgi on;
cgi_executor bash;
allow_method GET POST DELETE;
root /var/webserv/server2/cgi-bash/;
}
}
is_cgi on; と書いてあるところがCGI のディレクト リである。
課題要件で、CGI を実行するプログラムを指定できるようにしろと書いてあったのでこのように cgi_executor という設定を追加し、これをもとに実行する際には <cgi_executor> <request_path> みたいな形で実行する。個人的に、これではバイナリファイルが実行できないし、普通に shebang で実行すればいいじゃないかと思うのだが、課題がこうなっているので仕方ない。
CGI として実行するプログラムを特定する<cgi_executor> <request_path> という形で実行するのでは足りなくて、 <request_path> の先頭部分文字列のみが実行可能である可能性があるのである。
どういうことか例を出して説明すると、HTTPリクエス トで以下のような要求が来たとして、
GET /cgi-bin/cgi.py/subdir/subdir2
この際に、CGI スクリプト ファイルは /cgi-bin/cgi.py とする。
既にお察しの方もいるかもしれないが、 /cgi-bin/cgi.py/subdir/subdir2 はそのまま python3 /cgi-bin/cgi.py/subdir/subdir2 のようには実行できない。 RFC 的に正しい挙動としては、python3 /cgi-bin/cgi.py を実行し、その際にPATH_INFOという環境変数 に /subdir/subdir2 をセットする必要がある。
このCGI プロセスに渡すべき環境変数 のセットやCGI の実行やプロセス間通信は色々めんどい要素があるのだが、チームメンバーがやってくれました。偉大。
CGI レスポンスの種類RFC によるとCGI レスポンスには以下のような種類があり、それぞれWebサーバー側で行うべき処理が異なるので、CGI レスポンスのパースという処理がwebservに必要である。
CGI -Response = document-response | local-redir-response | client-redir-response | client-redirdoc-response
RFC 3875 - The Common Gateway Interface (CGI) Version 1.1 日本語訳
Document Response
これはもっとも標準的なCGI の出力である。
document-response = Content-Type [ Status ] *other-field NL response-body
RFC 3875 - The Common Gateway Interface (CGI) Version 1.1 日本語訳
基本的にCGI の出力を前からパースして、Content-Type が来たら Document Response と判断して構いません。
HTTPレスポンスの生成もContent-Typeセットして、StatusがあればHTTPレスポンスのStatus Codeにセットして、そんでresponse-bodyをそのままHTTPレスポンスBodyとして返して終わりです。
Client Redirect Response、Client Redirect Response with Document
client-redir-response = client-Location extension-field NL
client-redirdoc-response = client-Location Status Content-Type other-field NL response-body
RFC 3875 - The Common Gateway Interface (CGI) Version 1.1 日本語訳
こいつは、クライアント側でリダイレクトするというCGI レスポンスです。
HTTP Status Code がわかる人向けに言えば、300番系のレスポンスをWebサーバー側で生成してあげて返すだけです。
Client Redirect Response と Client Redirect Response with Document の違いはBNF を見てわかる通り、bodyがあるかどうかだけです。
Local Redirect Response
local-redir-response = local-Location NL
RFC 3875 - The Common Gateway Interface (CGI) Version 1.1 日本語訳
Local Redirect Response はwebserv初期設計を破壊した異端児です。こいつの対応のために設計を一部変えました。
何が異端児なのかというと、こいつだけ処理の流れが逆転するんですね。
まぁそれはともかく、こいつの説明を。
この Local Redirect Response はどのようなCGI レスポンスなのかというと、自分自身に対してもう一度リクエス トを送るようWebサーバーに依頼し、その結果を返す というものです。
The CGI script can return a URI path and query-string ('local-pathquery') for a local resource in a Location header field. This indicates to the server that it should reprocess the request using the path specified.
RFC 3875 - The Common Gateway Interface (CGI) Version 1.1 日本語訳
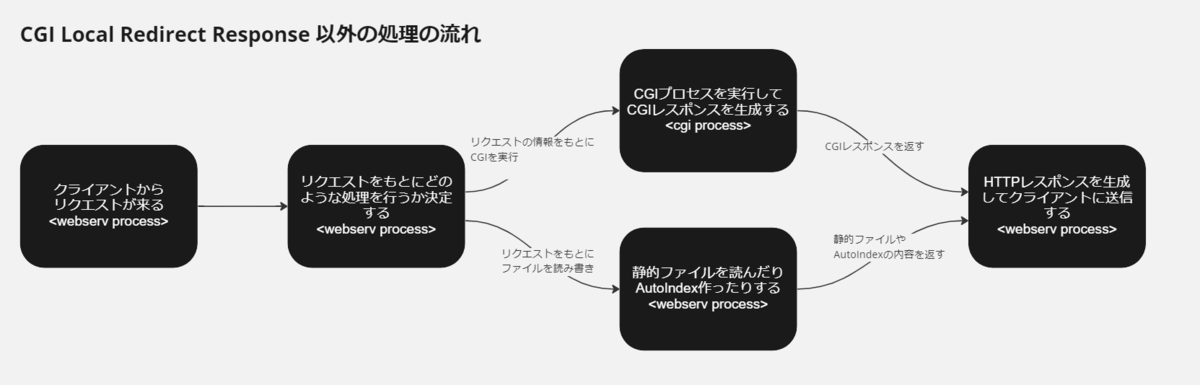
図にすると、コイツ以外のCGI レスポンスや静的ファイル、AutoIndexの処理は概ね以下のような流れになっています。
CGI Local Redirect Response 以外の処理の流れ
この Local Redirect Response の処理の流れはこうなっています。
CGI Local Redirect Response の処理の流れ
何しとんねん~~~~~~~
というわけで私の初期設計は破壊されましたが、賢いチームメンバーが「これLocalRedirectを反映させたリクエス トを接続済みソケットのHTTPリクエス トキューの2番目に入れれば良くね?」という天才的なアドバイス をくれたので一命を取り留めました。偉大。
github.com
Tips
ここからは開発中に「便利だなぁ~」「へぇ~~」って思ったことを書いてみます。
C++ の例外とResult<T> クラスC++ の例外を使うなーー!!(クソでか大声)
...は言い過ぎにしても、個人的には例外のような大域脱出はあまり好きではなく、さらに言えばC++ 98には例外の発生する可能性の有無をコンパイル 時にチェックしてくれるような機能が無いので余計に使いたくないのです。
個人的には go のような、関数の返り値の型からエラーが発生する可能性があるかどうか、エラーが発生したのならその返り値からエラー情報が欲しいわけです。
f, err := os.Open("filename.ext" )
if err != nil {
log.Fatal(err)
}
Error handling and Go - The Go Programming Language
C++ 98でもこんなことしたいな~と思っていたら良さげなものをまたまたAndroid のソースコード で見つけました。
https://cs.android.com/android/platform/superproject/+/master:system/libbase/include/android-base/result.h
Result<T> クラスです。
自分の実装はこちら
github.com
使い方はこんな感じ
#include "result.hpp"
#include <iostream>
using namespace result;
Result<int > succeed () {
return 10 ;
}
Result<void > succeedVoid () {
return Result<void >();
}
Result<void > fail () {
return Error ("This is error!" );
}
int main () {
Result<int > a = succeed ();
std ::cout << "----- a -----" << std ::endl ;
if (a.IsOk ()) {
std ::cout << "val: " << a.Ok () << std ::endl ;
}
if (a.IsErr ()) {
std ::cout << "err: " << a.Err ().GetMessage () << std ::endl ;
}
Result<void > b = succeedVoid ();
std ::cout << "----- b -----" << std ::endl ;
if (b.IsOk ()) {
std ::cout << "OK" << std ::endl ;
}
if (b.IsErr ()) {
std ::cout << "err: " << b.Err ().GetMessage () << std ::endl ;
}
std ::cout << "----- c -----" << std ::endl ;
Result<void > c = fail ();
if (c.IsOk ()) {
std ::cout << "OK" << std ::endl ;
}
if (c.IsErr ()) {
std ::cout << "err: " << c.Err ().GetMessage () << std ::endl ;
}
}
便利でしょ。
Result<T> クラスの実装にはAndroid のソースコード の他にRustのResult<T>クラスも参考にしました。
doc.rust-lang.org
webservにローカルネットワークの他端末からアクセス
頑張って実装したWebサーバー、せっかくならスマホ からアクセスしてみたいです。
というわけでwebservにローカルネットワークからアクセスする方法をご紹介します。
Discordのログから拾ってきました。
あるポート(80番ポートとか)を全ネットワークインターフェース(0.0.0.0)でlistenしている場合にはmDNSという機能を使って <computer名>.local(コンピュータ名が roxy なら roxy.local) で同じネットワークに接続された他のコンピュータからアクセスできます。これを使えばHerokuなどを使ってグローバルに公開せずともローカルネットワーク内限定ではありますがスマホ からアクセスできます。
https://e-words.jp/w/mDNS.html
またWindows 勢でWSLを使って開発をしている場合はWindows の方でWindows のポートをWSLのポートに接続してあげる必要があるので注意が必要です。
https://zenn.dev/solufa/articles/accessing-wsl2-from-mobile
って感じです。
この方法は別にwebservに限定したものではなく、汎用的に使える方法だと思うので、Web開発とかする機会があれば使えると思います。
NginxではFastCGI しか使えないので、CGI の挙動を確認したい場合にはApache を使うと良いと思いますよ。これは自分のチームメンバーがCGI 確認ツールを作ってくれました。偉大。
見落としそうなエラーハンドリング
いくつか見落としそうなエラーハンドリングがあったので雑に紹介
Broken Pipe シグナルは無視しよう
クライアント側が一方的に接続を切った際にBroken PipeのシグナルSIGPIPEが飛んできます。そしてこの SIGPIPE のデフォルト動作は プログラムをエラーとして終了 なのでちゃんとsigaction などで無視するようにして、write() の返り値でエラーはチェックするようにしましょう。
christina04.hatenablog.com
1クライアントがRSTパケットでネットワークを切断したらその時接続が確率されているすべてのソケットの接続が切れるなんで洒落にならんのでな。
TCP FINパケット受信後TCP FINパケットが飛んできたとき、それは正常なTCP 接続の終了であり、その時にepollは EPOLLRDHUP というイベントを通知する。
この EPOLLRDHUP はmanによるとこういうものらしい。
ストリームソケットの他端が、コネクションの close 、 またはコネクションの書き込み側の shutdown を行った。 (このフラグを使うと、エッジトリガーの監視を行う場合に、 通信のもう一端が閉じられたことを検知するコードを 非常に簡潔に書くことができる。)
「ほえー、TCP FINパケットが送られてきたらEPOLLRDHUPイベントが通知されるんか。ほなEPOLLRDHUPが来たらソケットをcloseしてしまえばええんか」
粉バナナ!!(これは罠だ)
dic.pixiv.net
これは罠で、クライアント側で後から送信したTCP FINパケットがネットワークの都合で先に送信したパケットよりも先にサーバーに到着する可能性がある。これを避けるためには EPOLLRDHUPを受け取った後にread()を行い、0が返ってくるのを確認する必要がある。
ymmt.hatenablog.com
epoll で標準ファイルの fd が監視できない理由
poll などは標準ファイルのfdを監視できるのだが、epollはできない。これは epoll_ctl() の man にも書いてある。
EPERM
対象ファイル fd が epoll に対応していない。 このエラーは fd が例えば通常ファイルやディレクト リを参照している場合にも起こり得る。
Man page of EPOLL_CTL
なぜ登録できないのかって思ったので調べてみた。
一応調べた結論としては、「標準ファイルにはpollインターフェースが無いからepollに登録できない」ということだった。
ほんとかなぁ?って思ってLinux のソースコード を少し読んでみたのでその記録を貼っておく。一応pollインターフェースっぽいものが標準ファイルには無いことは確認できたけど、なんで無いのかは知らない。賢い人教えてください。。
以下Disocrdのログコピペ。
regular file が epoll に登録できない件について調べている際にLinuxのコード読んだよなぁ~
regular file は epoll に登録できなくて、その理由が poll インターフェースが無いからという風にサイトには書いてあるんだけど、実際にその判定を行ってる箇所のコード昔見たよなーって思って調べ直した。
(番号は文章内で参照するために付けてるだけで意味はない)
1. pollインターフェースが無いからepollに登録できない: https://codehunter.cc/a/linux/epoll-on-regular-files
Linuxソースコード
2. epoll_ctl: https://elixir.bootlin.com/linux/latest/source/fs/eventpoll.c#L2077
3. file_can_poll: https://elixir.bootlin.com/linux/latest/source/include/linux/poll.h#L79
4. file構造体: https://elixir.bootlin.com/linux/latest/source/include/linux/fs.h#L940
5. file->f_op の型 file_operations: https://elixir.bootlin.com/linux/latest/source/include/linux/fs.h#L2093
6. file->f_op->poll がセットされている箇所を見ればわかるかもな
7. 例えば pipe だと pipe_poll がセットされている: https://elixir.bootlin.com/linux/latest/source/fs/pipe.c#L1223
8. Linuxのデファクトスタンダードのファイルシステムのext4の file->f_op を見ると poll が登録されていない! これじゃね?: https://elixir.bootlin.com/linux/latest/source/fs/ext4/file.c#L919
9. 上記の ext4_file_operation は regular file だった場合にセットされていることが確認できる: https://elixir.bootlin.com/linux/latest/source/fs/ext4/inode.c#L5003
完走した感想
(記事を書く)判断が遅い!(ここで鱗滝左近次からビンタを食らう)
とほほ。すいません(´・ω・`)
このwebservという課題は実は8月に終わっていて、記事書きたいな~でも面倒くさいな~って思ってたら4ヶ月経ってました。12月になってました。もう年が終わりそうです。
記事書くのが遅い件はこれくらいにして完走した感想(激ウマギャグ)ですが、とにかく楽しくて学びの多い最高の課題でした。
42Tokyoに入学した当初からこの課題楽しそうだなぁ~と思っていて、実際にやってみたら想像通り楽しかったです。なんならチームメンバーに恵まれたおかげもあって想像より楽しかったです。そして学びも多かった。
学びの面ではこの記事に書いた内容ももちろんそうだし、それ以外にもクライアントとのコネクション維持やC++ のクラス設計、ソケットプログラミングやI/Oの種類、Nginxのアーキテクチャ 、RFC を読める力、などなどかなりたくさんの学びがあって大満足でした。
開発期間は確か5~8月の3ヶ月くらい(多分)なはずで、自分はその間特に働いているわけでもなく42TokyoしてるかTwitter してるかだったので、起きてる時間はだいたいwebserv書いてたような気がします。そして生活リズムが終わってた。
自分含めチームメンバー全員が無職で42Tokyoをやっている俗に言うフルコミット勢なんですが、全員の生活リズムが狂っていたので、活動時間は夜0時から朝6時とかでした。その時間VCを繋いで、あーだこーだ言いながら毎日コード書いてました。そして朝7時位に寝て昼3時のおやつタイムに起きてました。終わっとる。でも、最高に楽しかったです。
42Tokyoは課題も楽しいですが、コミュニティにいる人間も楽しいので、ぜひみんなも42Tokyo入りましょう。(ダイレクトマーケティング )
42tokyo.jp
まぁ一応この記事は 42 Tokyo Advent Calendar 2022 の5日目の記事なのでね。42Tokyoの宣伝もしておきました。
明日は @sudo00 さんが 「zsh のmanを見ながらプロンプトを自作してみる」という記事を書くみたいです。面白そうですね!
現在時刻 2022年12月5日23時45分か...だいぶギリギリになっちゃったな...
そんなわけでギリギリアドベントカレンダー の担当日を超える前に記事を書き終えたので今日はここまで! ほなさいなら~~👋👋
参考資料
Nginx
HTTP
ソケットプログラミング / IO多重化



")
")
/VA/160Hz/1ms MBR/HDR/FreeSync Premium/HDMI×2,DisplayPort×1")