42Tokyoで minishell という課題があり, 完走したので感想書きます.
minishellについて
minishellとはbash っぽいシェルをC言語 で実装する課題.
実装する機能は以下の通り
readlineを使った入力と履歴の実装.
絶対パス もしくは $PATH 環境変数 を使った実行ファイルの実行 (/bin/ls や ls)ビルトインコマンド
echo (-nオプションのみ対応)cd (相対か絶対パス )pwd (オプションなし)export (オプションなし)unset (オプションなし)env (オプションなし)exit (オプションなし)
シングルクオートとダブルクオート
入出力リダイレクション (<, >, >>) と heredocument (<<)
パイプ (|)
環境変数 と $?ctrl-C(SIGINT), ctrl-\(SIGQUIT), ctrl-D(EOF)
っていう感じでbash っぽい小さなシェル(minishell)を作るという課題です.
この課題はチーム課題で, torusさん とチームを組んで取り組みました.
実装
実装したコードはここにあります.
github.com
動いている様子
gyazo.com
シェル全体の構成
全体を超大雑把に分けると以下のようなコンポーネント に分解できます.
入力処理(readline): JUN
Lexer & Parser: torus
CommandExecution: JUN
JUNと書いてあるのが自分が主に担当した部分で, torusと書いてあるのがtorusさんが主に担当した部分です.
大まかな設計は The Architecture of Open Source Applications という本の中にあるbash の章の中のbash のコンポーネント のアーキテクチャ 図を参考にしてコンポーネント を分け, その後それぞれに担当を決めました.
ここから先はこれらコンポーネント それぞれについての説明を書くのですが, 自分が担当した部分に関しては詳細に書けるのですが, 自分が担当していない部分に関しては少し大雑把な説明になるかもしれないです.
入力処理
入力処理はreadline を使って良いとのことなので, 使いました.
正直 readline が便利すぎてあまり入力処理について説明することは無いです. 強いて言うならシグナルハンドリングは少し気をつける必要がありますが, The GNU Readline Libraryを使った を見ればなんとかなります.
実はこの入力処理についてはちょっとした小話があるのですが, それはまた後ほど...
Lexer & Parser
Lexer (字句解析)
Lexerとは字句解析 機であり, 入力文字列を解釈し, 字句(ひとつの意味のある文字列単位)単位で取り出せるみたいな感じです. 字句はToken, 字句解析機はTokenizerとも呼ぶみたいです.
例えば入力が echo Hello I am "JUN" 'san' | cat なら以下のように取り出せるイメージです.
Token
Type
echo
EXPANDABLE
Hello
EXPANDABLE
am
EXPANDABLE
JUN
EXPANDABLE_QUOTED
san
NON_EXPANDABLE
|
PIPE
cat
EXPANDABLE
ja.wikipedia.org
Parser (構文解析 )
Lexerで字句単位に文字列を取り出せるようになったのでここでは取り出した字句を元に構文解析 を行い抽象構文木(AST) を作成します.
シェルが受け付ける文字列の文脈自由文法 (課題に必要な部分のみ)は バッカス・ナウア記法(BNF) を用いて以下のように表される.
command_line ::=
"\n"
| sequencial_commands delimiter "\n"
| sequencial_commands "\n"
delimiter ::=
";"
sequencial_commands ::=
piped_commands delimiter sequencial_commands
| piped_commands
piped_commands ::=
command "|" piped_commands
| command
command ::=
arguments
arguments ::=
redirection
| redirection arguments
| string
| string arguments
string ::=
expandable <no_space> string
| expandable
| not_expandable <no_space> string
| not_expandable
| expandable_quoted <no_space> string
| expandable_quoted
redirection ::=
"<" string
| ">" string
| ">>" string
| "<<" string
この文法に基づいて再帰下降構文解析 を行いASTを生成する.
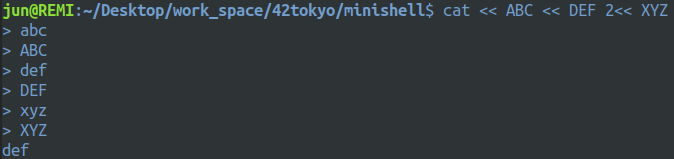
abc def | file < infile ; xyz ; のパース結果
CommandExecution
Lexer, Parser の処理が完了し, ASTが生成できたら今度はそれを元に実際にリダイレクションの処理やコマンドの実行などを行います.
今回は "Lexer & Parser" と "CommandExecution" を完全に分けて実装したので, ASTをそのまま使って実行するのではなくCommandExecution側で受け取りたい構造体(t_command_invocation)というのを予め定義しておき, ASTとt_command_invocationを変換する関数を最終的に作ることによって同時並行でそれぞれの担当箇所を実装できると共に, どちらか一方に変更があっても変換関数を修正すれば良いだけになります.
t_command_invocation は具体的には以下のような構造体です.
typedef struct s_command_invocation
{
t_cmd_redirection *output_redirections;
struct s_command_invocation *piped_command;
t_cmd_redirection *input_redirections;
const char **exec_and_args;
pid_t pid;
} t_command_invocation;
t_cmd_redirection はリダイレクションに関する情報を持つ片方向連結リストの構造体です. 具体的には以下の情報を持っています.
ファイルパス (heredocの場合は入力された文字列)
リダイレクションの種類(追記かどうか, heredocかどうかなど)
リダイレクションで指定されたファイルディスクリプタ
次のリダイレクションへのポインタ
piped_command はパイプの次のコマンドへのポインタです.
exec_and_args は実行するプログラムに渡す文字列配列です. int main(int argc, char **argv) と書いたら受け取れる argv の部分です.
pid はコマンド(プログラム)が子プロセスで実行された時のプロセスIDです.
fork() して作成した子プロセスを wait() して終了ステータスを取得するために使います. あと, fork()して作成した子プロセスを正しくwait()してあげないとゾンビプロセスになってしまうのでこれを避けるためにも子プロセスのpidは必要です.
リダイレクションの処理
リダイレクションの処理は基本的には dup2() などを使って標準入出力のfd(2>や3<みたいなfd指定の場合は指定のfd)をファイルのfdに置き換えれば出来ます.
気をつけるべき点としては, bash では複数リダイレクションが存在する時, そのfdのリダイレクションの中で最後リダイレクションのみが書き込みや読み込みが行われることです.
bash で echo hello > file1 > file2 > file3 と実行するとfile1とfile2はファイルは作成されるが, 何も書き込まれておらず, file3にのみ"hello"が書き込まれています. ちなみにzsh の場合だと全てのファイルに"hello" が書き込まれるという違いがあります.
入力の場合も同様で, cat < file1 < file2 の場合, 実際にcatコマンドの標準入力に繋がれるのは file2 のみです.
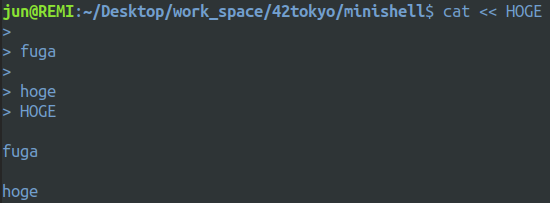
heredocument
heredocument はbash 特有の概念ではなく, いろんな言語に実装されている.
en.wikipedia.org
要は複数行文字列リテラル ということみたいです. bash においては << と区切り文字の組み合わせで始まり, もう一度区切り文字が出現するまでの文字列をコマンドの標準入力に流し込むというものになっています.
heredocumentの例
複数heredocumentの例
パイプとheredocumentを組み合わせた例
まぁ大体雰囲気はこんな感じです.
で, 実装の方なんですが, heredocumentの入力タイミングはParserの後, ASTをt_command_invocationに変換する関数内で行うようにしました. つまり, cat << EOF はparserが処理して, そこから先入力される文字列はParserではなくCommandExecution側で入力を受け付けて, 入力された文字列を構造体のメンバに保存します.
fd周りについてですが, ファイルのリダイレクションだとopen()すればよいのですが, heredocument はファイルを入力としているわけではないので, リダイレクションとは分けて考えるべきです.
しかし, 最初どういう風に実装されているか全然わからなかったのでbashのソースコード を見に行きました. そうするとどうやら親プロセスから子プロセスに対してheredocument用のpipeを繋いで文字列を渡しているようです.
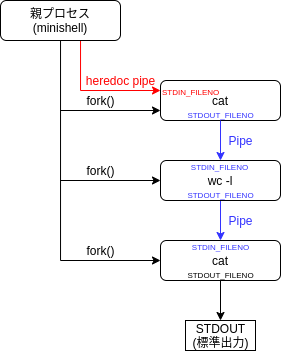
先程紹介した "パイプとheredocumentを組み合わせた例" を例に図にすると以下のような感じです.
パイプラインのコマンド間のパイプ以外にも, シェルのプロセスと子プロセス間のheredocument用のパイプを作成し, そのpipeに対してheredocumentで入力された文字列をwrite()することで実現出来ます.
プログラムの実行
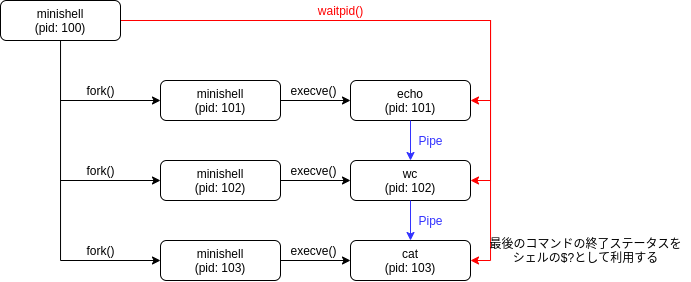
今回自分はシェルのパイプラインの実装はループで子プロセスを生成していくやり方にしました. echo hello | wc -l | cat を例として考えると以下の様になります.
シェルのパイプライン処理の実装方法はいくつかあるのですが, 複数コマンドが同時に 動くという点(並列実行)に気をつけましょう.
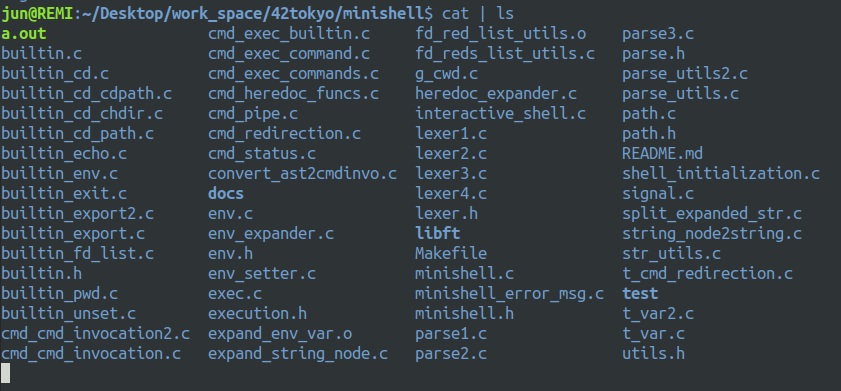
例えば bash で cat | ls とすると, catの実行が完了する前にlsの出力が先に出現します. これはcatの実行が完了してからlsを実行する逐次的な実行ではなく, cat と ls を並列に実行させているからです.
`cat` と `ls`が同時に実行され `cat` が入力待ちになっている
ビルトインコマンド
ビルトインコマンドというのはシェル側で実装してシェルに組み込まれているコマンドです.
ビルトインコマンドの実装自体は基本的にはbash のビルトインコマンドのヘルプとかを読みながら関数として実装すれば良いです.
で, 問題となるのはコマンドそのものというよりかはビルトインコマンドの実行方法です. ビルトインコマンドは外部のプログラムを呼び出すわけではないので execvp() などはしません.
ビルトインコマンドは単体で実行される場合とパイプラインとして実行される場合で実行方法が異なります.
ビルトインコマンド単体で実行される場合はfork()せずにシェルのプロセス上で対象の関数を呼び出します.
その際にリダイレクションが含まれている場合は標準入出力をdup() などを使って保存しておき, 後に復元する必要があります. こうしないとその後標準入出力が使えなくなります.
例えば echo hello > output.txtが入力された時, もしechoが外部コマンドならSTDOUT_FILENOをopen("output.txt", O_WRONLY | O_CREAT)で出力先ファイルのfdを使ってdup2(fd, STDOUT_FILENO) のように置き換えれば良いだけです. なぜなら外部コマンドを実行しているプロセスはシェルのプロセスではなく, シェルのプロセスからfork()された子プロセスであり, 子プロセスのfdがどうなろうと親プロセスには影響しないからです.
しかし, シェルのプロセスで実行するビルトインコマンドは話が違います. そのまま愚直にdup2(fd, STDOUT_FILENO)などとしようものなら標準出力はcloseされ, その後シェルが標準出力に書き込む手段が無くなります. なのでこのような悲惨な事態を避けるために dup(STDOUT_FILENO) のようにリダイレクション用のfdとは別に標準入出力のfdを複製して保持しておきます. そしてリダイレクションの処理を行っている時に複製した標準入出力のfdとリダイレクションで指定されたfd(2> みたいなやつ)が被ったらもう一度dup(複製した標準入出力のfd)をしてからファイルのfdに置き換えることで標準入出力のfdを失わないようにしながらリダイレクションを処理する必要があります.
そしてリダイレクションなどの処理が終わり, ビルトインコマンド関数の実行が完了したらリダイレクション用に開けていたfdを閉じて, 標準入出力のfdを元のfdに戻して完了です.
このようにビルトインコマンド単体の場合はシェルと同じプロセスで実行されるためリダイレクション周りなどは注意を払う必要が有ります.
次にパイプラインの中にビルトインコマンドがある場合, 例えば echo hello | cat のような場合です.
この場合, 外部コマンドを実行する時と同じ様にfork()して子プロセスを生成します. 違いはexecvp()で外部のプログラムを読み込んでメモリを別のプログラムに置き換えることはせず, ビルトインコマンドに対応した関数を呼び出して終了する点です.
ここまでの話で説明したとおりビルトインコマンドは単体の場合はシェルのプロセスで, パイプライン内の場合はシェルの子プロセスで実行されます. そして子プロセスの環境変数 やfdの変更, メモリの操作, カレントディレクト リの変更 は親プロセスに影響しません.つまりどういうことが起きるかというと, 以下のようなことが起きます.
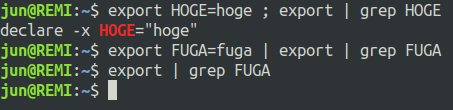
bash での実行例
パイプライン内で export した環境変数 が反映されていませんね. これは export は環境変数 を追加したけれど, コマンドがパイプライン内にあるのでexportは子プロセスで実行され, 親プロセスであるシェルのプロセス内の環境変数 には反映されていないのです.
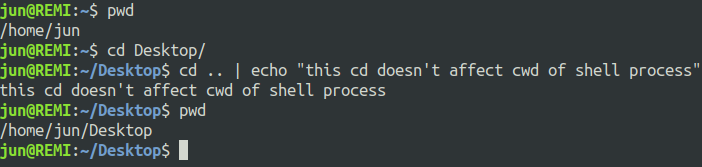
cdでも同様にパイプライン内で実行するとシステムコール chdir()が子プロセス内で実行されるためシェルのcwdは変わりません.
bash での実行例
こういうのを知るとなぜ export や unset, cdなどがビルトインコマンドとしてシェルに組み込まれているかがわかりますね.
その他
初めのころは, 環境変数 は文字列配列environをそのまま保持していて, 環境変数 を追加する時は文字列配列のメモリ領域を確保し直し(課題の制約でrealloc()は使えないので), environにもともと入っていたデータを新しい配列にコピーしその後最後の要素に新しい環境変数 の文字列("key=value "形式)を入れるようにしていました.
しかし, この方法はおすすめできません. なぜなら環境変数 の取得や追加, 削除などの操作に多くの手間が必要になりバグの原因になりますし拡張性が低いです. なので良い子は連結リストやハッシュテーブルなどの扱いやすいデータ構造で環境変数 を保持しておき, コマンドを実行する時に文字列配列に変換する関数を作りましょう.
今回自分は連結リストで環境変数 を保持するようにしました. 速度ガー! って思うかもしれませんが, 環境変数 の数なんて大して大きくなることは無いはずなので問題ないと判断しました. (問題が起きそうなら別のデータ構造に変えればいいだけ)
typedef struct s_var {
const char *key;
const char *value;
bool is_shell_var;
struct s_var *next;
} t_var;
入力処理に関しての小話
入力処理に関してはreadlineを使ったから苦労してない的なことを書きましたが, 実は自分のチームが課題を始めたころはreadlineは使えずTermcapを使って実装する必要がありました. (Termcapの部分はtorusさんがやってくれました)
en.wikipedia.org
このtermcapがかなり曲者のようでして, 入力処理の実装はかなり苦労していました. しかし, 自分達が課題を提出直前に課題変更があり, readlineが使えるようになりTermcapを使う必要が無くなったのと, 課題要件にheredocの追加が行われ, 話し合った結果Termcapによる入力処理の実装は破棄し, readlineによる入力処理を実装することにしました.
課題変更前はTermcapによる入力処理と履歴機能と文字列編集の実装のためにロープ木 )による文字列編集が実装されていました.
GitHub - torus/42-minishell at termcapありのバージョン からTermcapを使ったバージョンのコードが見れます. (heredocumentは実装されていません)
豆知識
ここではminishellをやる上で役に立つかもしれない豆知識を書いておきます. (自分用の備忘録でもある)
bash のコードリーディングbash のコードは1996年頃に書かれていて, 現代のC言語 のコードとは書き方が一部異なっており, それを知らないととても読みづらいです.
具体的には
インデントのサイズはスペース8
古いC言語 の規格では引数の型は関数ヘッダーの次の行に書く必要がある.
en.wikipedia.org
この書き方をK&Rスタイルと言うらしいです.
なのでbash のコードを読む時はエディタのインデントサイズを8にして, 古いC言語 の書き方を頭の片隅に置いておくとスムーズにコードが読めると思います.
GNU フラグパーサーecho -n -n hello や echo -nnnn hello と書いた時に echo -n hello と同じ挙動をするのはGNU のフラグパーサーライブラリであるgetoptの仕様によるものである.
en.wikipedia.org
www.gnu.org
完走した感想
いやー, 長かった. 4月に課題に取り組み始めてから提出するまで約3ヶ月かかりました. まぁ3ヶ月の間全てminishellやっていたというわけではなく競プロやったりフラクタル の実装したりちょくちょく寄り道したりしてましたが, それでも大変でした.
コミット数も42の課題では初めて1000コミット超えました. まぁPRやrevertなどのコミットがいっぱい入っているので全てのコミットがコードの実装を含んでいるというわけでもないですが.
この課題をするまでシェルというものが自分で実装できるものというイメージは全くありませんでしたが, 今回実装してみてシェルの内部での処理やUNIX プログラミングについて少し詳しくなり, シェルくらい頑張れば実装できるっしょっていう気持ちになりました.
また, 今回シェルを作ったことでこの課題に取り組む前と後でシェルに対する意識が大きく変わったように思えます. 課題に取り組む前は, シェルはブラックボックス って感じで, とりあえずなんか知らんけどコマンドを入力したら実行してくれるって感じでしたが, 今では内部でどのような処理が行われているかがわかっているためシェルを触っている時にシェルの実装側からの視点というものがわかるようになった気がします.
この記事ではあまり深堀りしてませんでしたが, cdを含むいくつかのビルトインコマンドはbash のhelpコマンドでは出てこない挙動などがあり, それを知るためにbash のソースコード を読んだりもしました. コミットが25年前(1996年)とかが普通にあり, 自分より年上のコードを読むのは新鮮でした. 25年前ともなると現在のC言語 の文法やインデントスタイルなどが違っていたりして読むのが大変でした.
今回始めてUNIX プログラミングと呼ばれるものを行っったのですが,「詳解UNIX プログラミング」という本がとてもとても役に立ちました.
UNIX とはなんぞやという説明からUNIX におけるファイルの扱い, シグナルやプロセス等々...UNIX プログラミングを行う上で必要な知識がここに書かれています. この本のおかげでminishellなんとかクリア出来たと言っても過言では無いくらいに役に立ちました. (自分の中では勝手に聖書と呼んでいます)
また, 今回一緒にチームを組んだtorusさんはキャリアの長いプログラマー の方で, 多くのことを教えて頂き大変勉強になりました. 豆知識のセクションに書いてある知識はtorusさんから教えてもらったものだったりします.
あと, 提出する直前で課題が大幅に変更されたのは堪えました. 特にtorusさんはその時点で既にTermcapに関わる入出力関係のコードを数週間掛けて千行以上書いていました. しかし, Termcapでの入出力をheredocに対応させる(複数行入力対応)こととreadlineの実装に切り替えるという2つの選択肢を考えた時に, ここまで書いてきた千行以上のコードを破棄し, readlineでの実装に舵を切ったのは凄いなぁと思いました. もし自分だったら惜しくて既存のコードに固執 してしまうかもしれません.
Termcapの削除に関するPR
github.com
今回の課題は今までの課題で一番重く, 実装量も多いため記事内で全てを解説しませんでした. 具体的なコードが見たい人はGitHub のリポジトリ を見てください.
github.com
とても大変でしたが, やりがいと学びのある良い課題でした.
といったところで今日はこのへんで. ではでは〜〜👋👋
参考リンク
シェル関係
パーサー関係
readline
Termcap
その他